Spoiled GRE Cartesian Readout#
In this notebook the sequence is composed with cmrseq and the input is a shepp-logan phantom, constructed with the phantominator package link
Imports#
[1]:
# Load TF and check for GPUs
import tensorflow as tf
physical_devices = tf.config.list_physical_devices('GPU')
if physical_devices:
print("Available GPUS: \n\t", "\n\t".join([str(_) for _ in physical_devices]))
tf.config.experimental.set_visible_devices(physical_devices[0], 'GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
from copy import deepcopy
# 3rd Party dependencies
import cmrseq
from tqdm.notebook import tqdm
from pint import Quantity
import pyvista
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# Project library cmrsim
import sys
sys.path.append("../..")
import cmrsim
from cmrsim.utils import particle_properties as part_factory
2022-08-15 08:24:10.643845: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-08-15 08:24:11.206291: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 22843 MB memory: -> device: 0, name: NVIDIA TITAN RTX, pci bus id: 0000:1a:00.0, compute capability: 7.5
1 Physical GPUs, 1 Logical GPUs
Construct Sequence#
[2]:
# Define MR-system specifications
system_specs = cmrseq.SystemSpec(max_grad=Quantity(40, "mT/m"), max_slew=Quantity(200., "mT/m/ms"),
grad_raster_time=Quantity(0.01, "ms"),
rf_raster_time=Quantity(0.01, "ms"))
fov = Quantity([202, 202], "mm")
matrix_size = (51, 51)
res = fov / matrix_size
adc_duration = Quantity(2., "ms")
pulse_duration = Quantity(1.5, "ms")
slice_thickness = Quantity(2, "cm")
flip_angle = Quantity(12, "degree").to("rad")
print("Resolution:", res)
n_dummy = 5
sequence_list = cmrseq.seqdefs.sequences.flash(system_specs,
slice_thickness=slice_thickness,
flip_angle=flip_angle,
pulse_duration=pulse_duration,
time_bandwidth_product=6,
matrix_size=matrix_size,
inplane_resolution=res,
adc_duration=adc_duration,
echo_time=Quantity(2., "ms"),
repetition_time=Quantity(4.5, "ms"),
dummy_shots=n_dummy)
# Add crusher gradients
crusher_area = Quantity(np.pi * 6, "rad") / system_specs.gamma_rad / res[0]
crusher = cmrseq.bausteine.TrapezoidalGradient.from_area(system_specs, orientation=np.array([1., 0., 0.]),
area=crusher_area.to("mT/m*ms"), delay=Quantity(4.5, "ms"))
sequence_list = [seq + cmrseq.Sequence([deepcopy(crusher)], system_specs) for seq in sequence_list]
k_grad, k_adc, t_adc = sequence_list[n_dummy+1].calculate_kspace()
t_center = Quantity(t_adc[matrix_size[0]//2], "ms")
combined_sequence_dummyshots = deepcopy(sequence_list[0])
combined_sequence_dummyshots.extend(sequence_list[1:n_dummy])
combined_sequence = deepcopy(sequence_list[n_dummy])
combined_sequence.extend(deepcopy(sequence_list[n_dummy+1:]))
Resolution: [3.9607843137254903 3.9607843137254903] millimeter
/scratch/jweine/conda/envs/tf29_pyvista/lib/python3.9/site-packages/pint/quantity.py:1313: RuntimeWarning: invalid value encountered in double_scalars
magnitude = magnitude_op(new_self._magnitude, other._magnitude)
/scratch/jweine/conda/envs/tf29_pyvista/lib/python3.9/site-packages/cmrseq/parametric_definitions/sequences/_gradient_echo.py:76: UserWarning: Echo time too short to be feasible, set TE to 3.34 millisecond
warn(f"Echo time too short to be feasible, set TE to {minimal_te}")
Extending Sequence: 100%|████████████████████████| 4/4 [00:00<00:00, 256.43it/s]
Extending Sequence: 100%|██████████████████████| 50/50 [00:00<00:00, 338.62it/s]
[3]:
plt.close("all")
fig = plt.figure(constrained_layout=True, figsize=(15, 8))
gs = fig.add_gridspec(2, 2)
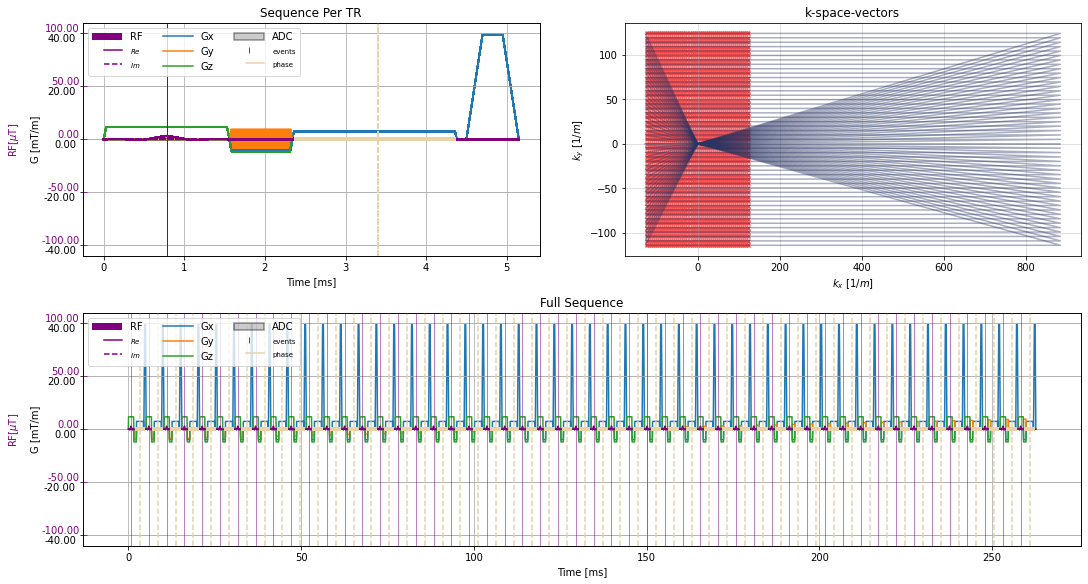
f3_ax1 = fig.add_subplot(gs[0, 0])
f3_ax1.set_title('Sequence Per TR')
f3_ax2 = fig.add_subplot(gs[0, 1])
f3_ax2.set_title('k-space-vectors')
f3_ax3 = fig.add_subplot(gs[1, 0:2])
f3_ax3.set_title('Full Sequence')
axes = fig.axes
cmrseq.plotting.plot_sequence(sequence_list[0], axes[0])
for tr_idx, s in enumerate(sequence_list[1:]):
cmrseq.plotting.plot_sequence(s, [fig.axes[-1], axes[0], axes[0], axes[0]], format_axes=False)
if tr_idx > n_dummy:
cmrseq.plotting.plot_kspace_2d(s, ax=axes[1], k_axes=[0, 1])
_ = cmrseq.plotting.plot_sequence(combined_sequence, axes=axes[2], format_axes=True)
Set up Phantom#
[4]:
import phantominator
x, y, z = 600, 600, 5
m0, t1, t2 = phantominator.shepp_logan(N=(x, y, z), MR=True, B0=1)
r = np.stack(np.meshgrid(np.linspace(-0.1, 0.1, x), np.linspace(-0.1, 0.1, y),
np.linspace(-0.1, 0.1, z)), axis=-1).astype(np.float32)
choose = np.where(m0 > 0)
r, m0, t1, t2 = [_[choose] for _ in (r, m0, t1, t2)]
n_new = r.shape[0]
random_offsets = np.random.uniform(-1, 1, size=(n_new, 3)) * 1e-4
r += random_offsets
properties = {"M0": m0.flatten().astype(np.float32),
"T1": t1.flatten().astype(np.float32) * 1000,
"T2": t2.flatten().astype(np.float32) * 1000,
"magnetization": part_factory.norm_magnetization()(n_new)}
m_init = properties.pop("magnetization")
print(f"Phantom with {n_new} particles")
Phantom with 466820 particles
Grid sequence and configure Bloch Module#
[5]:
class TrajMod(tf.Module):
@tf.function
def increment_particles(self, r, dt):
return r, dict()
t_comb_dummy, rf_comb_dummy, grad_comb_dummy, adc_on_comb_dummy = [np.stack(v) for v in cmrseq.utils.grid_sequence_list([combined_sequence_dummyshots, ])]
t_comb, rf_comb, grad_comb, adc_on_comb = [np.stack(v) for v in cmrseq.utils.grid_sequence_list(sequence_list[n_dummy:])]
print([v.shape for v in [t_comb, rf_comb, grad_comb, adc_on_comb]])
module_dummy = cmrsim.bloch.GeneralBlochOperator(name="dummy_shot_module", gamma=system_specs.gamma_rad.m_as("rad/mT/ms"),
time_grid=t_comb_dummy[0], gradient_waveforms=grad_comb_dummy,
rf_waveforms=rf_comb_dummy, device="GPU:0")
module_acq = cmrsim.bloch.GeneralBlochOperator(name="testmodule", gamma=system_specs.gamma_rad.m_as("rad/mT/ms"),
time_grid=t_comb[0], gradient_waveforms=grad_comb,
rf_waveforms=rf_comb, adc_events=adc_on_comb, device="GPU:0")
[(51, 20349), (51, 20349), (51, 20349, 3), (51, 2, 20349)]
Run Simulation#
[6]:
print(f"Simulating {t_comb_dummy.shape[0] + t_comb.shape[0]*t_comb.shape[1]} steps for {m_init.shape[0]} isochromates")
for rbatch, mbatch, dict_batch in tqdm(tf.data.Dataset.from_tensor_slices((r, m_init, properties)).batch(int(1.5e6)), "Phantom Batches"):
mbatch, rbatch = module_dummy(trajectory_module=TrajMod(), initial_position=rbatch, magnetization=mbatch, repetition_index=0, **dict_batch)
for rep_idx in tqdm(range(t_comb.shape[0]), desc="TR index", leave=False):
_ = module_acq(trajectory_module=TrajMod(), initial_position=rbatch, magnetization=mbatch, repetition_index=rep_idx, run_parallel=False, **dict_batch)
Simulating 1037800 steps for 466820 isochromates
2022-08-15 08:24:30.047295: I tensorflow/compiler/xla/service/service.cc:170] XLA service 0x55bfcf5f5370 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2022-08-15 08:24:30.047332: I tensorflow/compiler/xla/service/service.cc:178] StreamExecutor device (0): NVIDIA TITAN RTX, Compute Capability 7.5
2022-08-15 08:24:30.094100: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:263] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
2022-08-15 08:24:30.833004: I tensorflow/core/platform/default/subprocess.cc:304] Start cannot spawn child process: No such file or directory
2022-08-15 08:24:31.783838: I tensorflow/compiler/jit/xla_compilation_cache.cc:478] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
WARNING:tensorflow:5 out of the last 5 calls to <function GeneralBlochOperator._call_core at 0x7f9c3d305d30> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
WARNING:tensorflow:6 out of the last 6 calls to <function GeneralBlochOperator._call_core at 0x7f9c3d305d30> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has reduce_retracing=True option that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
Reconstruct Image#
[7]:
# Non uniform combined
time_signal = tf.stack(module_acq.time_signal_acc, axis=0).numpy().reshape(matrix_size[::-1])
centered_projection = tf.signal.fft(time_signal).numpy()
centered_k_space = tf.signal.fft(centered_projection).numpy()
image = tf.signal.fftshift(tf.signal.ifft2d(tf.roll(tf.signal.ifftshift(centered_k_space, axes=(0, 1)), -1, axis=1)), axes=(0, 1)).numpy()
time_per_seg = t_adc - t_center.m_as("ms")
freq_per_seg = np.fft.fftfreq(n=time_per_seg.shape[0], d=time_per_seg[1]-time_per_seg[0])
print(time_signal.shape, centered_projection.shape, time_per_seg.shape, freq_per_seg.shape, image.shape)
(51, 51) (51, 51) (51,) (51,) (51, 51)
Plot 2D representation of specific single line acquisitions#
If the configured adc only acquires the exact k-space locations the acquired time signal equals the k-space line
[8]:
# Plot 2D Lines
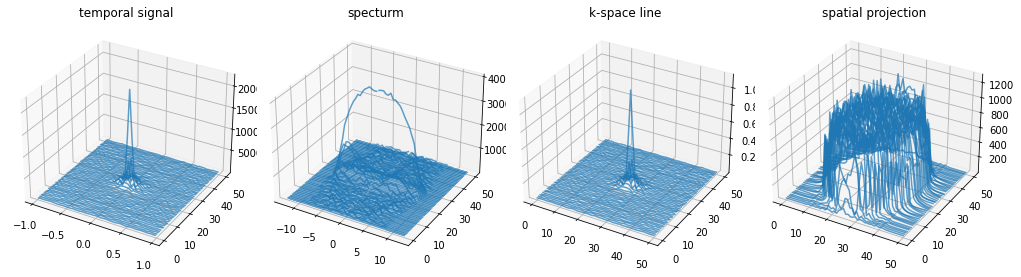
fig, axes = plt.subplots(1, 4, figsize=(14, 2.5))
[a.grid(True) for a in axes]
[a.set_title(t) for a, t in zip(axes, ["temporal signal", "specturm", "k-space line", "spatial projection"])]
[a.legend(["real", "Imaginary"]) for a in axes]
for ky in range(0, time_signal.shape[0], 10):
axes[0].plot(time_per_seg, np.real(time_signal[ky]), color="C0", linestyle="-", alpha=0.7)
axes[0].plot(time_per_seg, np.imag(time_signal[ky]), color="C1", linestyle="-", alpha=0.7)
axes[1].plot(freq_per_seg, np.real(centered_projection[ky]), color="C0", linestyle="-", alpha=0.7)
axes[1].plot(freq_per_seg, np.imag(centered_projection[ky]), color="C1", linestyle="-", alpha=0.7)
axes[2].plot(np.arange(freq_per_seg.shape[0]), np.real(centered_k_space[ky]), color="C0", linestyle="-", alpha=0.7)
axes[2].plot(np.arange(freq_per_seg.shape[0]), np.imag(centered_k_space[ky]), color="C1", linestyle="-", alpha=0.7)
axes[3].plot(np.arange(freq_per_seg.shape[0]), np.real(image[ky]), color="C0", linestyle="-", alpha=0.7)
axes[3].plot(np.arange(freq_per_seg.shape[0]), np.imag(image[ky]), color="C1", linestyle="-", alpha=0.7)
fig.tight_layout()

Plot 3D representation of simulation results#
If the configured adc only acquires the exact k-space locations the acquired time signal equals the k-space line
[9]:
# Plot all PE-lines in 3D
plt.close("all")
from mpl_toolkits.mplot3d.axes3d import Axes3D
fig, axes = plt.subplots(1, 4, subplot_kw={'projection': '3d'}, figsize=(14, 4))
[a.set_title(t) for a, t in zip(axes, ["temporal signal", "specturm", "k-space line", "spatial projection"])]
for ky in range(time_signal.shape[0]):
axes[0].plot(time_per_seg, np.ones_like(time_signal[ky].real) * ky, np.abs(time_signal[ky]), color="C0", linestyle="-", alpha=0.7)
axes[1].plot(freq_per_seg, np.ones_like(centered_projection[ky].real) * ky, np.abs(centered_projection[ky]), color="C0", linestyle="-", alpha=0.7)
axes[2].plot(np.arange(freq_per_seg.shape[0]), np.ones_like(centered_k_space[ky].real) * ky, np.abs(centered_k_space[ky]), color="C0", linestyle="-", alpha=0.7)
axes[3].plot(np.arange(freq_per_seg.shape[0]), np.ones_like(image[ky].real) * ky, np.abs(image[ky]), color="C0", linestyle="-", alpha=0.7)
fig.tight_layout()
Plot Image#
[10]:
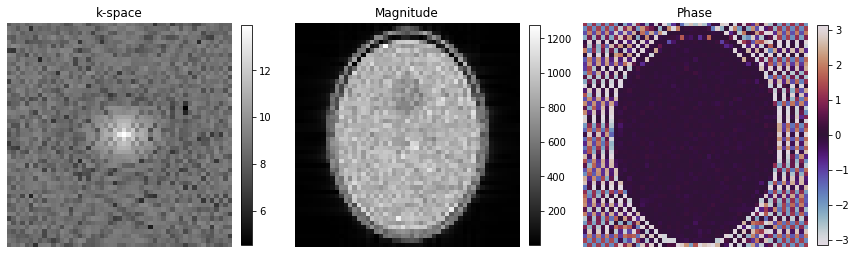
# Show images
fig, axes = plt.subplots(1, 3, figsize=(12, 5))
kspace_plot = axes[0].imshow(np.log(np.abs(np.squeeze(centered_k_space))), cmap="gray")
fig.colorbar(kspace_plot, ax=axes[0], fraction=0.045, pad=0.04)
abs_plot = axes[1].imshow(np.abs(np.squeeze(image)), cmap="gray")
fig.colorbar(abs_plot, ax=axes[1], fraction=0.045, pad=0.04)
phase_plot = axes[2].imshow(np.angle(np.squeeze(image)), cmap="twilight", vmin=-np.pi, vmax=np.pi)
fig.colorbar(phase_plot, ax=axes[2], fraction=0.045, pad=0.04)
[_.axis("off") for _ in axes]
[_.set_title(t) for _, t in zip(axes, ["k-space", "Magnitude", "Phase"])]
fig.tight_layout()
Create Thumbnail#
[23]:
plt.close("all")
fig = plt.figure(constrained_layout=True, figsize=(15, 12))
gs = fig.add_gridspec(4, 6)
fig.add_subplot(gs[0, 0:3])
fig.add_subplot(gs[0, 3:])
fig.add_subplot(gs[1, 0:])
fig.add_subplot(gs[2:, 0:2])
fig.add_subplot(gs[2:, 2:4])
fig.add_subplot(gs[2:, 4:6])
axes = fig.axes
[a.set_title(t) for a, t in zip(axes, ['Sequence Per TR', 'k-space-vectors', 'Full Sequence', "k-space", "Magnitude", "Phase"])]
cmrseq.plotting.plot_sequence(sequence_list[0], axes[0])
for tr_idx, s in enumerate(sequence_list[1:]):
cmrseq.plotting.plot_sequence(s, [fig.axes[-1], axes[0], axes[0], axes[0]], format_axes=False)
if tr_idx > n_dummy:
cmrseq.plotting.plot_kspace_2d(s, ax=axes[1], k_axes=[0, 1])
_ = cmrseq.plotting.plot_sequence(combined_sequence, axes=axes[2], format_axes=True)
kspace_plot = axes[3].imshow(np.log(np.abs(np.squeeze(centered_k_space))), cmap="gray")
fig.colorbar(kspace_plot, ax=axes[3], fraction=0.045, pad=0.04, location="bottom")
abs_plot = axes[4].imshow(np.abs(np.squeeze(image)), cmap="gray")
fig.colorbar(abs_plot, ax=axes[4], fraction=0.045, pad=0.04, location="bottom")
phase_plot = axes[5].imshow(np.angle(np.squeeze(image)), cmap="twilight", vmin=-np.pi, vmax=np.pi)
fig.colorbar(phase_plot, ax=axes[5], fraction=0.045, pad=0.04, location="bottom")
[_.axis("off") for _ in axes[3:]]
fig.savefig("static_bloc_spoiled_gre.svg")
[ ]: