
Publication
Semantic Foggy Scene Understanding with Synthetic Data
Christos Sakaridis,
Dengxin Dai,
and Luc Van Gool
International Journal of Computer Vision (IJCV), 2018
[PDF]
[Final PDF: view-only]
[BibTeX]
[arXiv]
The first PDF above is a post-peer-review,
pre-copyedit version of the article published in
International Journal of Computer Vision.
The final authenticated version is available online at
https://doi.org/10.1007/s11263-018-1072-8
or in a view-only mode through the "Final PDF" above.
News
- The Foggy Driving download package is updated. It now also contains the path list for the 21 images with dense fog in the Foggy Driving-dense subset, which is used in our follow-up ECCV 2018 and IJCV 2019 works on semantic scene understanding in dense fog. (2019-12-06)
Foggy Datasets
We present two distinct datasets for semantic understanding of foggy scenes: Foggy Cityscapes and Foggy Driving.
Foggy Cityscapes derives from the Cityscapes dataset and constitutes a collection of synthetic foggy images generated with our proposed fog simulation that automatically inherit the semantic annotations of their real, clear counterparts. Due to licensing issues, the main dataset modality of foggy images is only available for download at the Cityscapes website. This is also the case for semantic annotations as well as other modalities which are shared by Foggy Cityscapes and Cityscapes. On the contrary, the auxiliary Foggy Cityscapes modalities of denoised depth maps and transmittance maps are available at this website in the following packages:
|
|
Transmittance maps (8-bit) for foggy scenes in train, val, and test sets 15000 images (5000 images x 3 fog densities) MD5 checksum |
|
|
Transmittance maps (8-bit) for foggy scenes in trainextra set 19997 images MD5 checksum |

|
Depth maps (denoised and complete) for train, val, and test sets 5000 files (MATLAB MAT-files) Download credentials MD5 checksum |

|
Depth maps (denoised and complete) for trainextra set 19997 files (MATLAB MAT-files) Download credentials MD5 checksum |
Foggy Driving is a collection of 101 real-world foggy road scenes with annotations for semantic segmentation and object detection, used as a benchmark for the domain of foggy weather. We provide dense, pixel-level semantic annotations of these images for the 19 evaluation classes of Cityscapes. Bounding box annotations for objects belonging to 8 of the above classes that correspond to humans or vehicles are also available.
Foggy Cityscapes
We develop a fog simulation pipeline for real outdoor scenes and apply it to the complete set of 25000 images in the Cityscapes dataset to obtain Foggy Cityscapes. We also define a refined set of 550 training+validation Cityscapes images out of the original 3475 ones, which yield high-quality synthetic fog. The resulting collection of 550 foggy images is termed Foggy Cityscapes-refined.
We provide three different versions of Foggy Cityscapes for the 5000 training+validation+testing Cityscapes images, each characterized by a constant attenuation coefficient which determines the fog density and the visibility range. The values of the attenuation coefficient are 0.005, 0.01 and 0.02m-1 and correspond to visibility ranges of 600, 300 and 150m respectively. For the 20000 extra training Cityscapes images, we provide a single version with attenuation coefficient of 0.01m-1. Examples of Foggy Cityscapes scenes for varying fog density are shown below.
| Clear weather | 600m visibility | 300m visibility | 150m visibility |
|---|---|---|---|

|

|

|

|

|

|

|

|
Foggy Driving
Foggy Driving consists of 101 color images depicting real-world foggy driving scenes. 51 of these images were captured with a cell phone camera in foggy conditions at various areas of Zurich, and the rest 50 images were collected from the web. The maximum image resolution in the dataset is 960x1280 pixels.
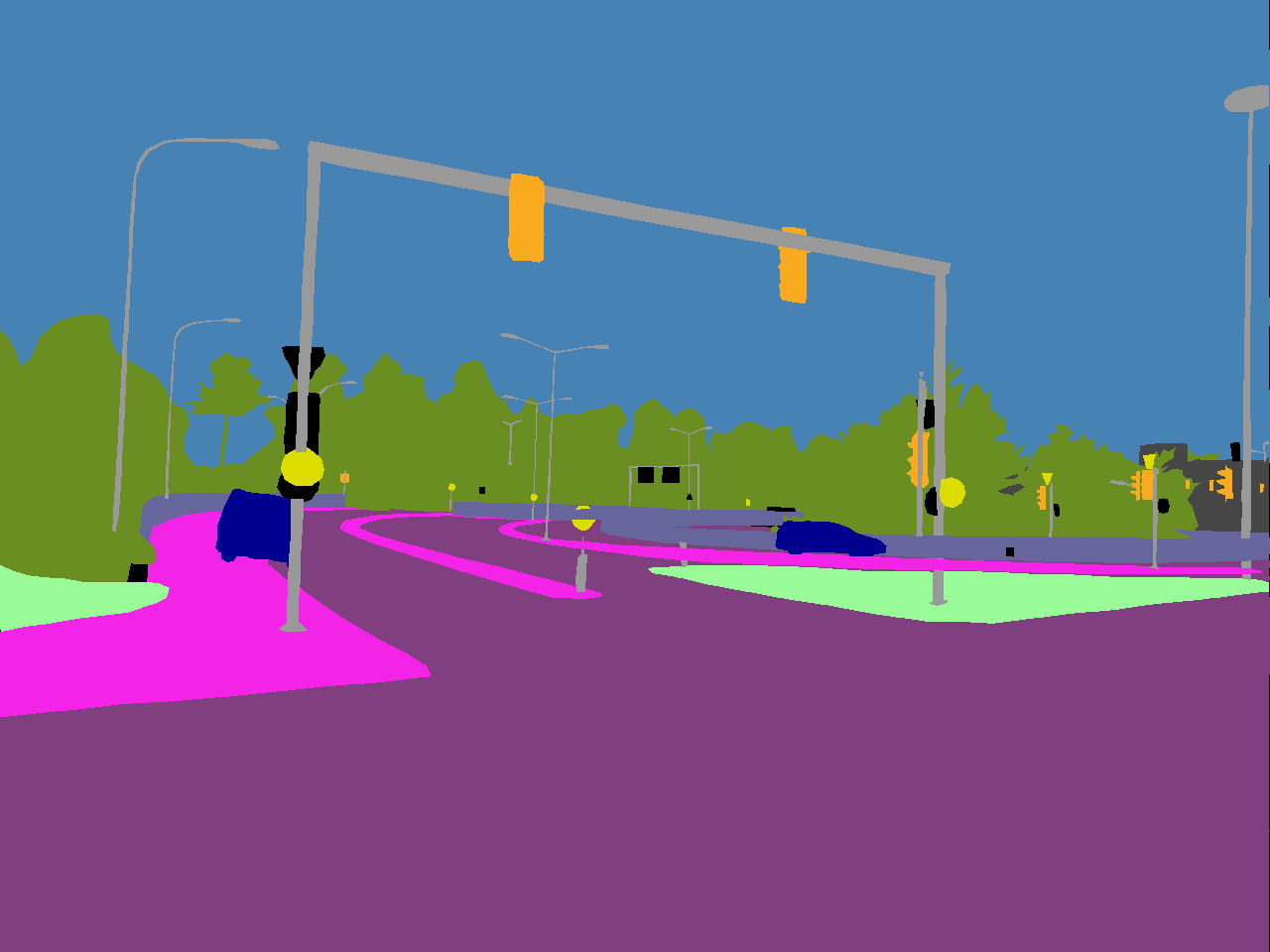
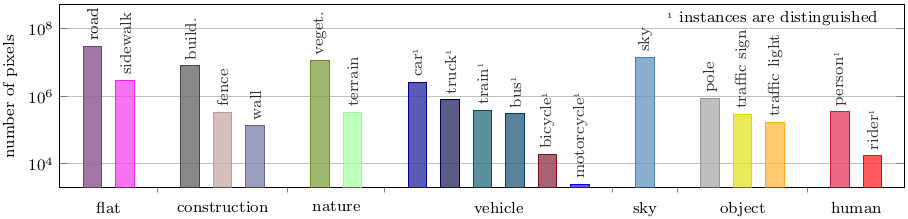
Foggy Driving features pixel-level semantic annotations for the set of 19 classes that are used for evaluation in Cityscapes. Individual instances of the 8 classes from the above set which correspond to humans or vehicles are labeled separately, which affords bounding box annotations for these classes. In total, Foggy Driving contains more than 500 annotated vehicles and almost 300 annotated humans. Given its moderate scale, this dataset is meant for evaluation purposes and we recommend against using its annotations to train semantic segmentation or object detection models. Example images along with their semantic annotations as well as overall annotation statistics are presented below.

|

|

|

|
|

|

|

|
Results
We show that our partially synthetic Foggy Cityscapes dataset can be used per se for successfully adapting modern convolutional neural network (CNN) models to the condition of fog. Our experiments on semantic segmentation and object detection evidence that fine-tuning "clear-weather" Cityscapes-based models on Foggy Cityscapes improves their performance significantly on the real foggy scenes of Foggy Driving.
We present two learning approaches in this context, one using standard supervised learning and another using semi-supervised learning. In the former, supervised approach, we use Foggy Cityscapes-refined with its fine ground-truth annotations inherited from Cityscapes to fine-tune the clear-weather model to fog. In the latter, novel semi-supervised approach, we augment the training set used for fine-tuning with Foggy Cityscapes-coarse comprising 20000 synthetic foggy trainextra Cityscapes images, where the missing fine annotations for these images are substituted with the predictions of the clear-weather model for the clear-weather counterparts of the images. In the following, we present selected experiments and results from our article.
Semantic Segmentation
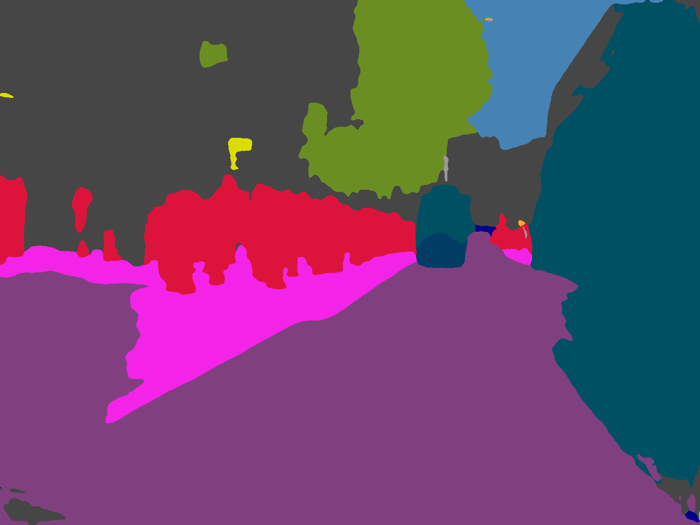
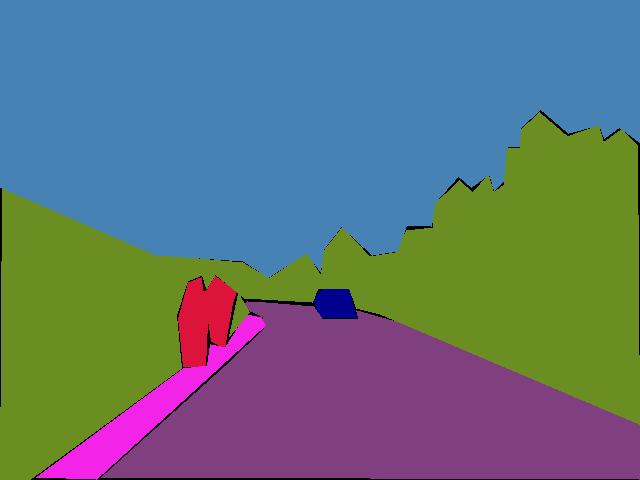
We experiment with the state-of-the-art RefineNet model. We compare the mean intersection over union (IoU) performance of our adaptation approaches on Foggy Driving against the original, clear-weather RefineNet model trained on Cityscapes. The mean IoU scores on Foggy Driving are 44.3% for the clear-weather model, 46.3% for the model fine-tuned with the supervised approach, and 49.7% for the model fine-tuned with the semi-supervised approach. Qualitative results on Foggy Driving for the clear-weather RefineNet model and our semi-supervised adaptation approach are shown below.
| Foggy image | Ground truth | Clear-weather RefineNet | Ours |
|---|---|---|---|

|

|

|
|
|
|
|

|

|

|
|

|

|
Object Detection
We experiment with the modern Fast R-CNN model, using multiscale combinatorial grouping for object proposals. We first train a model on the original, clear-weather Cityscapes dataset which serves as our baseline. We then fine-tune this model with our supervised adaptation approach on Foggy Cityscapes-refined and compare the average precision (AP) performance of the two models on Foggy Driving. AP for car is 30.5% for the clear-weather model and 35.3% for the fine-tuned model, while mean AP over the 8 classes with distinct instances is 11.1% for the clear-weather model and 11.7% for the fine-tuned model. Qualitative car detection results on Foggy Driving for the clear-weather Fast R-CNN model and our supervised adaptation approach are depicted below.
| Ground truth | Clear-weather Fast R-CNN | Ours |
|---|---|---|

|

|

|

|

|

|

|

|

|
Pretrained Models
Semantic Segmentation
We provide the central pretrained models for both semantic segmentation networks which are used in the experiments of our article, i.e. the dilated convolutions network (DCN) and RefineNet.
-
DCN: These models have been trained with the standard supervised approach that
we consider in the article. Templates of the Caffe train, test and solver
prototxt files that were used to train these models as well as of testing
scripts are also included in the respective downloads.
- Dilation10 Cityscapes model fine-tuned on Foggy Cityscapes-refined (500 MB) with attenuation coefficient 0.01, referred to as FT-0.01 in the article.
- Dilation10 Cityscapes model fine-tuned on Foggy Cityscapes-refined (500 MB) with attenuation coefficient 0.005, referred to as FT-0.005 in the article.
- Dilation10 Cityscapes model fine-tuned on Foggy Cityscapes-refined (500 MB) with attenuation coefficient 0.02, referred to as FT-0.02 in the article.
-
RefineNet:
-
RefineNet ResNet-101 Cityscapes model fine-tuned on Foggy Cityscapes-refined (410 MB)
with attenuation coefficient 0.01.
This model has been trained with the standard supervised approach that we consider in the article. -
RefineNet ResNet-101 Cityscapes model fine-tuned on Foggy Cityscapes-refined and Foggy Cityscapes-coarse (410 MB)
with attenuation coefficient 0.01.
This model has been trained with the novel semi-supervised approach that we present in the article.
-
RefineNet ResNet-101 Cityscapes model fine-tuned on Foggy Cityscapes-refined (410 MB)
with attenuation coefficient 0.01.
For more details on how to test or further train these models, please refer to the original implementations of the two networks.
Object Detection
We also provide the central pretrained models for the object detection network Fast R-CNN we use in our experiments, as well as code for testing these models on Foggy Driving.
-
Fast R-CNN models: Templates of the Caffe test prototxt files
and testing scripts that were used to test these models are also included in
the respective downloads.
- Fast R-CNN model trained on original Cityscapes trainval (500 MB)
- Fast R-CNN model fine-tuned on Foggy Cityscapes-refined (500 MB) with attenuation coefficient 0.005, referred to as FT-0.005 in the article.
- Code for testing Fast R-CNN on Foggy Driving: based on the Fast R-CNN source code repository; please consult the included read-me file for installing and using this code to test the above pretrained Fast R-CNN models on Foggy Driving.
Code
The source code for our fog simulation pipeline is available on GitHub.
Citation
Please cite our publication if you use our datasets, models or code in your work.
Moreover, in case you use the Foggy Cityscapes dataset, please cite additionally the Cityscapes publication, and in case you use our fog simulation code, please cite additionally both the Cityscapes publication and the SLIC superpixels publication.