Computer Vision Laboratory, ETH Zurich
Switzerland, 2020-2021
| Andrey Ignatov | Jagruti Patel | Radu Timofte |
| andrey@vision.ee.ethz.ch | patelj@student.ethz.ch | timofter@vision.ee.ethz.ch |

Abstract: Bokeh is an important artistic effect used to highlight the main object of interest on the photo by blurring all out-of-focus areas. While DSLR and system camera lenses can render this effect naturally, mobile cameras are unable to produce shallow depth-of-field photos due to a very small aperture diameter of their optics. Unlike the current solutions simulating bokeh by applying Gaussian blur to image background, in this paper we propose to learn a realistic shallow focus technique directly from the photos produced by DSLR cameras. For this, we present a large-scale bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR with 50mm f/1.8 lenses. We use these images to train a deep learning model to reproduce a natural bokeh effect based on a single narrow-aperture image. The experimental results show that the proposed approach is able to render a plausible non-uniform bokeh even in case of complex input data with multiple objects. The dataset, pre-trained models and codes used in this paper are provided below.
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Original
Original
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered
 Pixel Camera
Pixel Camera
 Rendered
Rendered

One of the biggest challenges in the bokeh rendering task is to get high-quality real data that can be used for training deep models. To tackle this problem, a large-scale
The captured image pairs are not aligned exactly, therefore they were first matched using SIFT keypoints and RANSAC method. The resulting images were then cropped to their intersection part and downscaled so that their final height is equal to 1024 pixels. Finally, we computed a coarse depth map for each wide depth-of-field image using the Megadepth model. These maps can be stacked directly with the input images and used as an additional guidance for the trained model. From the resulting
Note: The full EBB! dataset will be available after the end of the
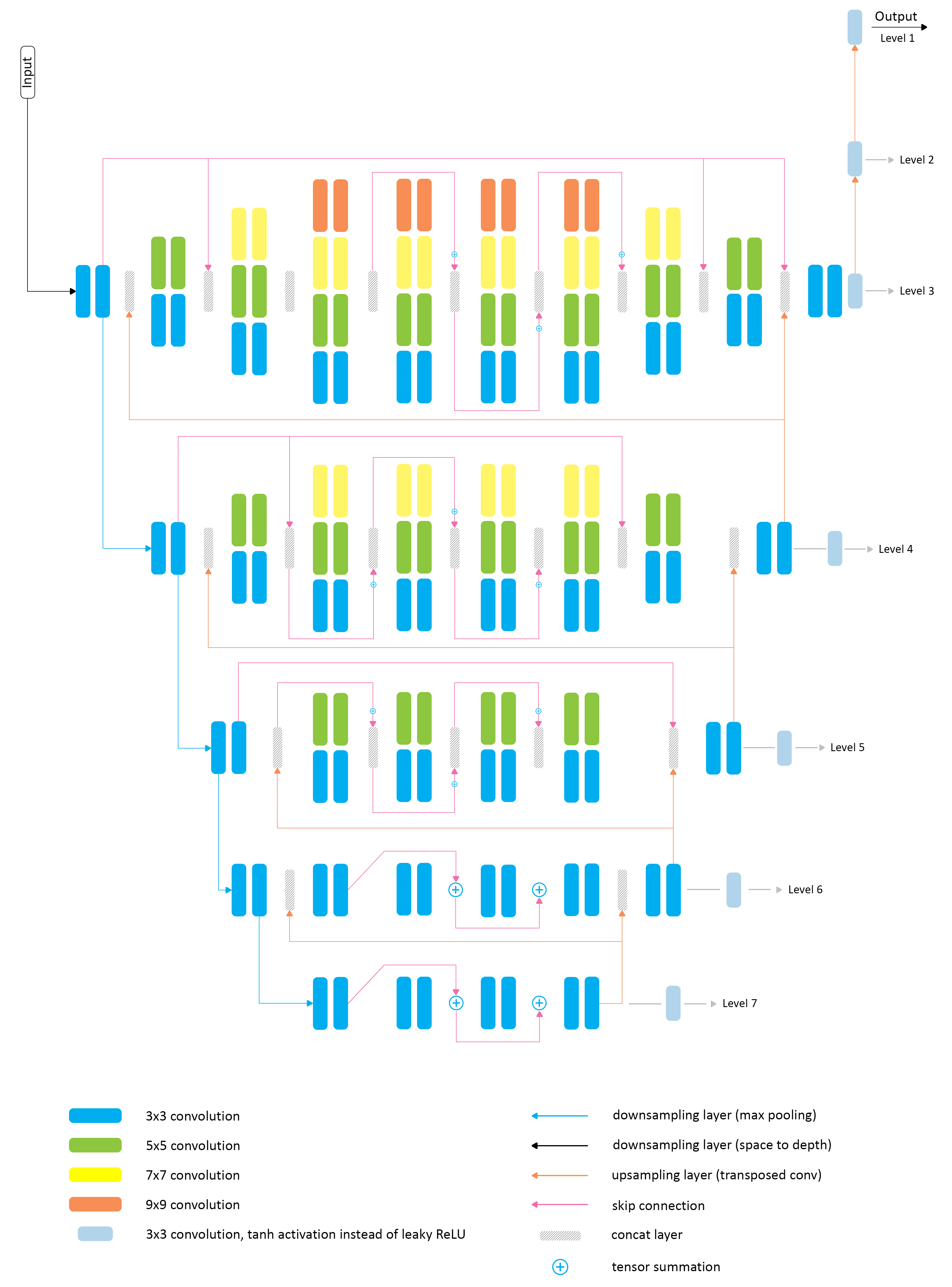
Bokeh effect simulation problem belongs to a group of tasks dealing with both global and local image processing. High-level image analysis is needed here to detect the areas on the photo where the bokeh effect should be applied, whereas low-level processing is used for rendering the actual shallow depth-of-field images and refining the results. Therefore, in this work we base our solution on the PyNET architecture designed specifically for this kind of tasks: it is
The proposed architecture has a number of blocks that are processing feature maps in parallel with convolutional filters of different size (from 3×3 to 9×9), and the outputs of the corresponding convolutional layers are then concatenated, which allows the network to learn a more diverse set of features at each level. The outputs obtained at lower scales are upsampled, stacked with feature maps from the upper level and then subsequently processed in the following convolutional layers. Instance normalization is used in all convolutional layers that are processing images at lower scales (levels 2-5). We are additionally using two transposed convolutional layers on top of the main model that upsample the images to their target size.
The model
"Rendering Natural Camera Bokeh Effect with Deep Learning",
Computer Vision Laboratory, ETH Zurich
Switzerland, 2020-2021