Computer Vision Laboratory, ETH Zurich
Switzerland, 2017-2021
| Andrey Ignatov | Nikolay Kobyshev | Radu Timofte | Kenneth Vanhoey | Luc Van Gool |
| ihnatova@vision.ee.ethz.ch | nk@vision.ee.ethz.ch | timofter@vision.ee.ethz.ch | vanhoey@vision.ee.ethz.ch | vangool@vision.ee.ethz.ch |

Abstract: Despite a rapid rise in the quality of built-in smartphone cameras, their physical limitations - small sensor size, compact lenses and the lack of specific hardware, - impede them to achieve the quality results of DSLR cameras. In this work we present an end-to-end deep learning approach that bridges this gap by translating ordinary photos into DSLR-quality images. We propose learning the translation function using a residual convolutional neural network that improves both color rendition and image sharpness. Since the standard mean squared loss is not well suited for measuring perceptual image quality, we introduce a composite perceptual error function that combines content, color and texture losses. The first two losses are defined analytically, while the texture loss is learned in an adversarial fashion. We also present DPED, a large-scale dataset that consists of real photos captured from three different phones and one high-end reflex camera. Our quantitative and qualitative assessments reveal that the enhanced image quality is comparable to that of DSLR-taken photos, while the methodology is generalized to any type of digital camera.
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified

To tackle the general photo enhancement problem by mapping low-quality phone photos into photos captured by a professional DSLR camera, we introduce a large-scale DPED dataset that consists of photos taken synchronously in the wild by three smartphones and one DSLR camera. The devices used to collect the data are iPhone 3GS, BlackBerry Passport, Sony Xperia Z and Canon 70D DSLR. To ensure that all devices were capturing photos simultaneously, they were mounted on a tripod and activated remotely by a wireless control system.
In total, over 22K photos were collected during 3 weeks, including 4549 photos from Sony smartphone, 5727 from iPhone and 6015 photos from BlackBerry; for each smartphone photo there is a corresponding photo from the Canon DSLR. The photos were taken during the daytime in a wide variety of places and in various illumination and weather conditions. The images were captured in automatic mode, we used default settings for all cameras throughout the whole collection procedure.
The synchronously captured photos are not perfectly aligned since the cameras have different viewing angles, focal lengths and positions. To address this, we performed additional non-linear transformations based on SIFT features to extract the intersection part between phone and DSLR photos, and then used the obtained aligned image fragments to extract patches of size 100x100 pixels for CNN training (139K, 160K and 162K pairs for BlackBerry, iPhone and Sony, respectively). These patches constituted the input data to our CNN.

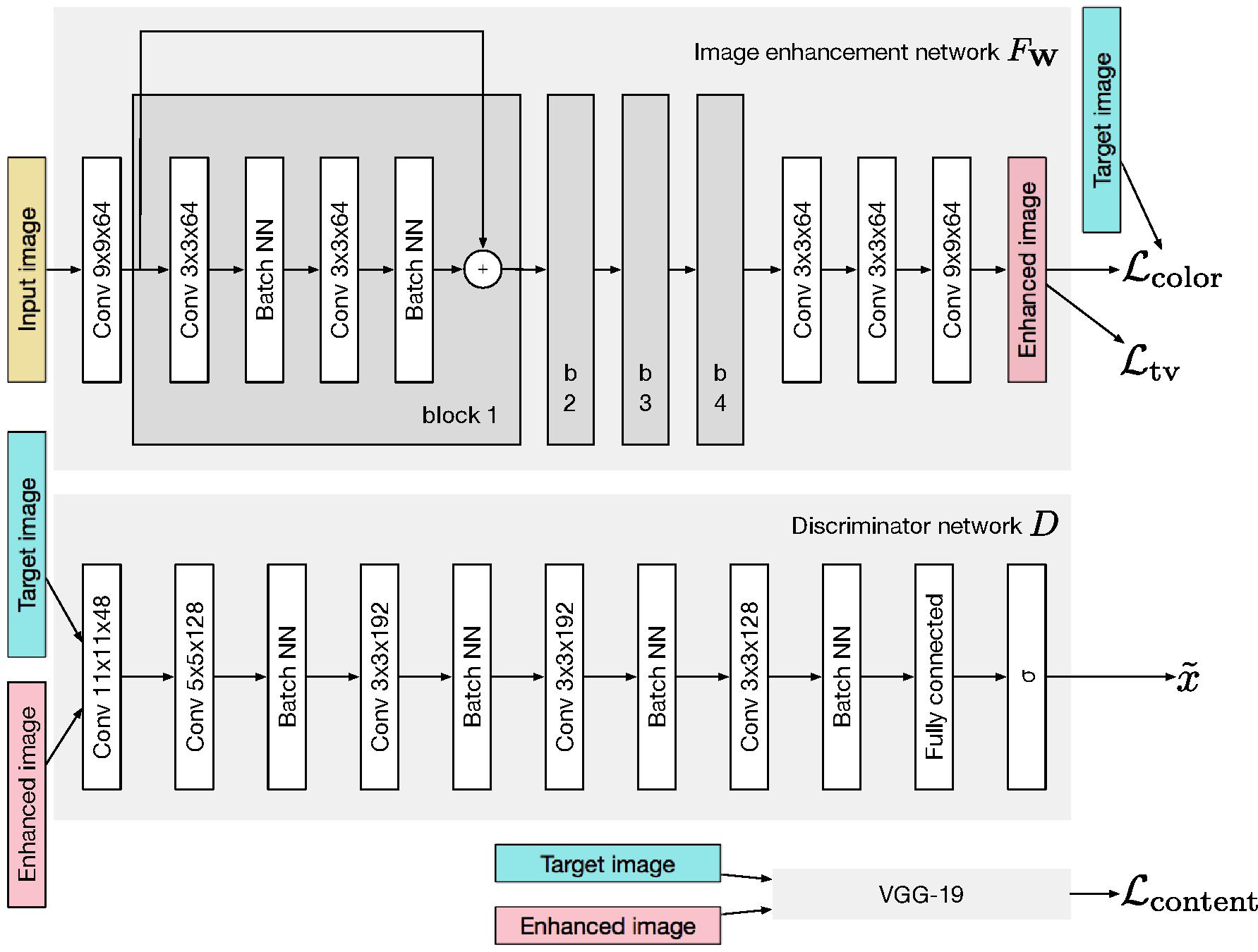
Image enhancement is performed using a
| ● |
the enhanced image should be close to the target (DSLR) photo in terms of colors. To measure the difference between them, we apply |
| ● |
to measure texture quality of the enhanced image, we train a separate |
| ● |
a distinct |
All these losses are then summed, and the system is trained as a whole with the backpropagation algorithm to minimize the final weighted loss.
TensorFlow implementation of the proposed models and the whole training pipeline is available in our github repo
Pre-trained models + standalone code to run them can be downloaded separately here
Prerequisites: GPU + CUDA CuDNN + TensorFlow (>= 1.0.1)
"DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks",
In
Computer Vision Laboratory, ETH Zurich
Switzerland, 2017-2021